Latest Trends in AI Hardware Amazing Map (2024-2030): From GPU Dominance to Memory-Centric Computing
The latest trends in AI hardware reflect a fundamental shift from general-purpose GPUs to specialized silicon, with memory bandwidth replacing raw compute as the primary bottleneck. By 2026, the industry will complete its transition from training-focused architectures to inference-optimized designs, while chiplet-based systems emerge as the dominant paradigm for high-performance AI workloads.
Introduction
The AI hardware landscape is undergoing its most significant transformation since deep learning went mainstream. What began as researchers repurposing gaming GPUs has evolved into a multi-billion-dollar race to build purpose-built silicon for artificial intelligence.
Why This Shift Matters Now
Today’s latest trends in AI hardware reveal an industry at an inflection point: NVIDIA’s H100 and Blackwell architectures remain supply-constrained due to hyperscaler demand from OpenAI-like workloads, while companies like Google, Amazon, and Apple quietly deploy custom accelerators that challenge the GPU’s decade-long dominance.
The Economics Are Changing
Training massive foundation models once dominated infrastructure spending, but inference workloads, the actual deployment of AI models, now represent the faster-growing segment. Memory bandwidth, not floating-point performance, has become the limiting factor for transformer-based architectures. Edge devices now run AI workloads that required data center hardware just three years ago.
What You’ll Learn
This analysis maps the latest trends in AI hardware across five distinct waves, from NVIDIA’s GPU era through the coming age of chiplet ecosystems and memory-centric computing. Each wave builds on the previous generation while introducing architectural innovations that redefine what’s possible.
The Five Waves of AI Hardware Evolution
Wave 1 (2015-2020): GPU Dominance Era
How NVIDIA Built an Accidental Monopoly
The modern AI hardware story begins with NVIDIA’s accidental monopoly. Graphics processing units, originally designed for rendering video game textures, turned out to be remarkably efficient at the matrix multiplication operations that power neural networks.
The CUDA Ecosystem Lock-In
NVIDIA’s CUDA programming environment gave researchers a mature software ecosystem, while competitors struggled to match the combination of hardware performance and developer tooling. This created switching costs that persist even as custom silicon offers better performance-per-watt metrics.
Tesla V100 and A100: Purpose-Built for AI
The Tesla V100, announced in 2017, represented the first GPU purpose-built for AI training. With 640 Tensor Cores delivering 125 teraflops of mixed-precision performance, the V100 became the standard datacenter accelerator for deep learning.
Its successor, the A100, announced in 2020, doubled performance while introducing multi-instance GPU capabilities that let cloud providers partition a single chip across multiple workloads. According to NVIDIA’s technical documentation, the A100’s third-generation Tensor Cores and 40GB of HBM2 memory established architectural patterns that continue to influence the latest trends in AI hardware design.
Wave 2 (2020-2024): Custom AI Chip Emergence
Why Hyperscalers Stopped Paying the NVIDIA Tax
Hyperscalers spending billions on GPU infrastructure began questioning why they were paying NVIDIA’s margins for general-purpose hardware when their workloads were highly specialized. Google’s TPU (Tensor Processing Unit) architecture demonstrated that custom silicon designed specifically for neural network operations could deliver significantly better performance per watt than GPUs running the same workloads.
Google’s TPU Advantage
Google Cloud’s TPU v5e pods now power many of the company’s production AI services, offering what Google’s research papers describe as superior economics for both training and inference compared to GPU alternatives. The TPU’s systolic array architecture optimizes for the matrix multiplications central to transformer models, while reducing energy consumption by eliminating unnecessary features present in general-purpose processors.
Amazon and Intel Join the Custom Silicon Race
Amazon Web Services followed with Trainium for training and Inferentia for inference, positioning these custom chips as cost-effective alternatives to NVIDIA hardware for customers running standardized workloads. Intel’s Gaudi 2 and Gaudi 3 accelerators target the same market, emphasizing open software ecosystems and competitive pricing.
AMD’s Unified Architecture Approach
AMD’s MI300 series challenges NVIDIA directly with unified CPU-GPU architectures that address one of the latest trends in AI hardware: eliminating data movement bottlenecks between processing and memory.
The Real Insight
Most people assume GPUs are the future of AI hardware, but in reality, GPUs are becoming a transitional layer while custom silicon quietly takes over the economics of large-scale deployment.
Wave 3 (2024-2026): Edge AI Proliferation
The Quiet Mobile Revolution
While datacenter AI grabbed headlines, a quieter revolution happened in mobile devices. Apple’s Neural Engine, introduced with the A11 Bionic in 2017, has evolved through multiple generations to deliver trillion-operation-per-second performance in smartphones.
Apple’s M4: Datacenter Power in Your Laptop
The M4 chip’s Neural Engine processes machine learning workloads at 38 trillion operations per second while consuming a fraction of the power required by datacenter accelerators. This represents one of the most significant latest trends in AI hardware: the migration of inference workloads from cloud to edge.
Qualcomm Brings AI to Every Phone
Qualcomm’s Snapdragon 8 Gen 3 includes AI processing capabilities that enable real-time language models, image generation, and voice processing directly on mobile devices. Edge inference now exceeds cloud inference for many applications because network latency and privacy concerns make local processing preferable to round-tripping data to remote servers.
The Economics of Edge AI
Gartner’s AI chip market forecasts project that edge AI processor shipments will exceed datacenter AI accelerators by unit volume in 2026, even as datacenter chips maintain revenue dominance due to higher prices.
Automotive Drives Edge AI Adoption
Automotive applications particularly drive this trend, with Tesla’s FSD computer and competitors’ autonomous driving systems deploying hundreds of TOPS (trillions of operations per second) of AI processing per vehicle. Mobile NPU performance benchmarks now rival discrete GPUs from just a few years ago.
Wave 4 (2025-2027): Memory-Centric Computing Revolution
The Dirty Secret of Modern AI Chips
The dirty secret of modern AI accelerators is that raw compute capability increasingly sits idle waiting for data. Transformer models with billions of parameters require moving massive amounts of weight data from memory to processing cores, and memory bandwidth, not arithmetic throughput, determines actual performance.
HBM3E: The New Performance Bottleneck
HBM3E (High Bandwidth Memory 3E) technology from Samsung and SK Hynix delivers 1.15 TB/s of memory bandwidth per chip stack, yet this still can’t keep pace with the data requirements of the largest language models. This bottleneck represents one of the most critical latest trends in AI hardware architecture.
TSMC’s Packaging Bottleneck
TSMC’s advanced packaging techniques like CoWoS (Chip-on-Wafer-on-Substrate) enable closer integration between compute and memory, but manufacturing capacity constraints create bottlenecks. According to semiconductor industry reports, CoWoS capacity limitations directly contribute to AI chip supply shortages.
Processing-in-Memory: The Solution
Processing-in-memory (PIM) architectures address this by moving computation closer to where data lives, rather than shuttling data to distant compute cores. Samsung’s HBM-PIM and similar approaches integrate processing logic directly into memory chips, reducing data movement and energy consumption.
Why Memory Bandwidth Now Matters More Than FLOPS
The memory wall problem in transformer models makes this architectural shift inevitable, you can’t economically scale AI systems by adding more compute cores if they spend most of their time waiting for memory. This explains why NVIDIA’s Blackwell architecture emphasizes memory bandwidth improvements alongside compute enhancements.
AMD’s 3D Memory Integration
AMD’s MI300X integrates 192GB of HBM3 memory with compute dies using advanced 3D stacking. The real competition in the latest trends in AI hardware is no longer about who builds the fastest processor, but who solves the memory bandwidth challenge most elegantly.
Wave 5 (2026-2030): AI Superchips and Chiplet Ecosystems
The End of Monolithic Chips
The future of high-performance AI hardware lies not in building larger monolithic processors, but in composing systems from specialized chiplets connected through high-bandwidth interconnects.
NVIDIA’s Blackwell: Two Chips Acting as One
NVIDIA’s Blackwell architecture demonstrates this approach with its multi-die design connected via NVLink interfaces, delivering 20 petaflops of AI performance by essentially treating two chips as one logical processor.
UCIe: The Standard That Changes Everything
The UCIe (Universal Chiplet Interconnect Express) standard, backed by Intel, AMD, TSMC, and other industry players, enables mixing and matching chiplets from different vendors. This modular approach addresses several challenges simultaneously.
Why Chiplets Win: Physics and Economics
Chiplets are replacing monolithic GPUs in the latest trends in AI hardware because physics and economics demand it. As chip features shrink toward the limits of current lithography, making larger monolithic dies becomes exponentially more expensive due to defect rates.
The Market Shift to Modular Design
Chiplet architectures let manufacturers build equivalent processing power from multiple smaller, higher-yield components. According to industry analysis, chiplet-based designs could capture over 40% of the high-end AI accelerator market by 2027.
True AI Superchips Emerge
This wave also sees the emergence of true AI superchips, systems that integrate compute, memory, networking, and specialized accelerators for specific operations like video encoding or cryptographic processing into unified packages. These aren’t general-purpose processors with AI features bolted on, but ground-up designs where AI workload optimization drives every architectural decision.
Related Questions AI Search Users Ask
Why Are AI Chips Currently Supply-Constrained?
Hyperscaler Demand Explosion
The shortage of AI accelerators stems from multiple converging factors. Hyperscaler demand from companies like Microsoft (OpenAI infrastructure), Meta (Llama training), and Anthropic (Claude development) has created unprecedented consumption of high-end GPUs. NVIDIA’s H100 allocation extends months into the future, with enterprise customers paying premiums for immediate availability.
TSMC Manufacturing Bottleneck
Manufacturing capacity at TSMC represents the fundamental bottleneck. The most advanced AI chips require 5nm or 3nm process nodes, where fab capacity is limited, and demand spans AI accelerators, smartphone processors, and other high-performance computing applications.
Export Controls Fragment the Market
Export controls add complexity by fragmenting the market. U.S. restrictions on selling advanced AI chips to China have created dual product lines, with manufacturers developing lower-capability versions for restricted markets while allocating advanced chips to unrestricted customers. This reduces economies of scale and complicates supply chain planning.
What’s the Difference Between AI Training and Inference Hardware?
Training: High Precision, Massive Scale
Training involves iteratively adjusting billions of parameters across massive datasets, requiring high-precision arithmetic (typically FP32 or FP16) and extreme parallelism across thousands of accelerators. A single training run for a large language model might consume thousands of GPUs for weeks, performing calculations that must maintain numerical precision to ensure model convergence.
Inference: Low Latency, High Volume
Inference runs trained models on new data to generate predictions, translations, images, or other outputs. These workloads prioritize latency over throughput and can often use reduced precision (INT8 or even INT4 quantization) without significantly impacting output quality. A single inference accelerator might serve thousands of user requests per second.
The 2025-2026 Economic Crossover
The economic crossover happening in 2025-2026 makes inference the larger market despite lower per-chip prices. While training a GPT-class model happens once (or periodically), that model then runs billions of inferences serving users. Market research from IDC suggests inference workload growth will outpace training by 3x through 2027, fundamentally shifting which latest trends in AI hardware receive investment priority.
Why Different Products Exist
This explains why NVIDIA offers both A100/H100 for training and L4/L40 for inference, why Amazon built separate Trainium and Inferentia products, and why inference-optimized architectures increasingly emphasize memory bandwidth over raw compute throughput.
How Do Custom AI Chips Compare to GPUs?
Performance-Per-Watt Advantage
Custom AI accelerators deliver superior performance-per-watt for specific workloads at the cost of flexibility and ecosystem maturity. Google’s TPU documentation shows 2-3x better performance-per-watt than contemporary GPUs when running Google’s production models, primarily because the architecture eliminates hardware features needed for general computing but irrelevant to neural network operations.
The Software Ecosystem Gap
The software ecosystem gap remains the custom chip’s biggest challenge. CUDA’s maturity means thousands of optimized libraries, debugging tools, and trained developers exist for NVIDIA hardware. Custom accelerators require building equivalent tooling from scratch, though efforts like OpenXLA (cross-platform accelerator compiler) aim to create portable software stacks.
Total Cost of Ownership for Hyperscalers
Total cost of ownership (TCO) analysis for hyperscalers increasingly favors custom silicon despite higher development costs. A hyperscaler running standardized workloads across thousands of accelerators can amortize custom chip development expense across massive deployments.
AWS Trainium chips reportedly cost 40% less than equivalent GPU performance for customers running supported frameworks like PyTorch and TensorFlow, making custom approaches among the most economically significant latest trends in AI hardware.
When GPUs Still Make Sense
For enterprises without hyperscale deployment volumes or with diverse workloads requiring flexibility, GPUs remain the pragmatic choice. The custom chip advantage scales with deployment size and workload standardization.
What Role Does Memory Play in Modern AI Accelerators?
Memory Bandwidth as Primary Bottleneck
Memory bandwidth has become the primary performance determinant in the latest trends in AI hardware, surpassing compute throughput for many real-world workloads. Large language models with hundreds of billions of parameters require loading those parameters from memory for every calculation.
The Scale of the Problem
A 175-billion parameter model using 16-bit precision needs 350GB just to store weights, and that data must flow to compute cores billions of times per second.
HBM vs GDDR: Why Custom Memory Wins
HBM (High Bandwidth Memory) vs GDDR comparison shows why custom memory solutions dominate AI accelerators. HBM3 delivers over 819 GB/s bandwidth per stack compared to GDDR6’s ~448 GB/s, though at significantly higher cost and complexity.
The Memory Wall Problem
The memory wall problem in transformer models means that doubling compute capability while keeping memory bandwidth constant often yields minimal performance improvement because processors spend more time waiting for data.
Near-Memory Computing Solutions
Near-memory computing solutions represent one of the most promising latest trends in AI hardware architecture. By integrating processing capability directly into memory chips or positioning compute dies micrometers away from memory through advanced packaging, these approaches reduce data movement energy and latency.
Samsung’s Processing-in-Memory Innovation
Samsung’s HBM-PIM and similar processing-in-memory technologies could eventually eliminate the traditional separation between memory and compute entirely for AI workloads. This architectural shift explains why memory bandwidth specifications now appear prominently in AI accelerator marketing alongside traditional metrics like TFLOPS performance.
Industry Insider Insights: What Tech Analysts Are Watching
Hyperscalers vs Chip Vendors: The Real Competition
The most sophisticated observers of the latest trends in AI hardware focus not on individual chip announcements but on architectural transitions that reshape competitive dynamics. The real competition is no longer NVIDIA vs AMD, it’s hyperscalers vs chip vendors.
Companies like Google, Amazon, and Microsoft increasingly design their own silicon optimized for internal workloads, reducing dependence on merchant chip suppliers and keeping architectural innovations proprietary.
Chiplet Adoption Timeline
Chiplet adoption represents the clearest indicator of where the industry heads next. The UCIe standard, gaining traction, suggests that by 2027-2028, mixing compute chiplets from one vendor with memory chiplets from another and I/O chiplets from a third becomes standard practice.
This modular approach fundamentally changes competitive dynamics from “who builds the best complete chip” to “who builds the best component ecosystem.”
Edge AI Doubling Prediction
Edge AI doubling predictions rest on solid data: automotive deployments alone will add billions of TOPS of distributed AI processing as autonomous driving systems scale. Combined with AI-enabled smartphones, IoT devices, and industrial equipment, edge AI processing capacity will exceed centralized datacenter AI by aggregate throughput if not by individual workload size.
GPUs as a Transitional Layer
The GPU as transitional layer thesis suggests that just as CPUs didn’t disappear when GPUs became essential for AI, GPUs won’t disappear as custom silicon proliferates. Instead, GPUs become the flexible development platform where new models are created before being optimized for custom inference accelerators.
NVIDIA’s dominance in training workloads likely to persists even as inference shifts toward specialized architectures.
Memory Bandwidth Over Compute
Memory bandwidth becoming more important than raw compute represents the least understood but most impactful of current latest trends in AI hardware. The next generation of AI workloads, multimodal models processing video, audio, and text simultaneously, will exacerbate memory bandwidth requirements beyond what current architectures can economically deliver.
2026 AI Hardware Trend Predictions Index
| Prediction | Confidence | Key Drivers | Companies to Watch |
|---|---|---|---|
| GPU supply constraints continue through 2026 | High (85%) | TSMC capacity limits, hyperscaler demand growth, geopolitical fragmentation | NVIDIA, TSMC, Samsung |
| Edge AI adoption doubles in mobile/automotive | Very High (90%) | Latency requirements, privacy concerns, and autonomous vehicle deployment | Apple, Qualcomm, Tesla, Mobileye |
| Chiplet architectures capture 40%+ of the high-end AI market | Medium (70%) | Manufacturing economics, UCIe standardization, design flexibility | Intel, AMD, TSMC, UCIe Consortium |
| Memory bandwidth becomes the primary specification (over FLOPS) | High (80%) | Transformer model scaling, memory wall bottleneck, PIM maturation | Samsung, SK Hynix, Micron |
| Custom silicon reaches cost parity with GPUs for inference | Medium (75%) | Hyperscaler volume, software ecosystem maturation, TCO optimization | Google, Amazon, Microsoft |
| AI workload power consumption triggers datacenter redesigns | High (85%) | 700W+ accelerators, cooling infrastructure limits, and electricity costs | NVIDIA, AMD, datacenter REITs |
| Open-source AI hardware specifications gain enterprise adoption | Low-Medium (60%) | RISC-V maturation, geopolitical hedging, and customization demand | RISC-V International, SiFive |
Understanding the Predictions
These predictions about latest trends in AI hardware reflect both technical trajectories and economic forces reshaping the industry. The highest-confidence predictions involve physical constraints (manufacturing capacity, power delivery) while lower-confidence predictions involve ecosystem dynamics (open-source adoption, custom silicon economics), where network effects and switching costs create path dependencies that could override pure technical merit.
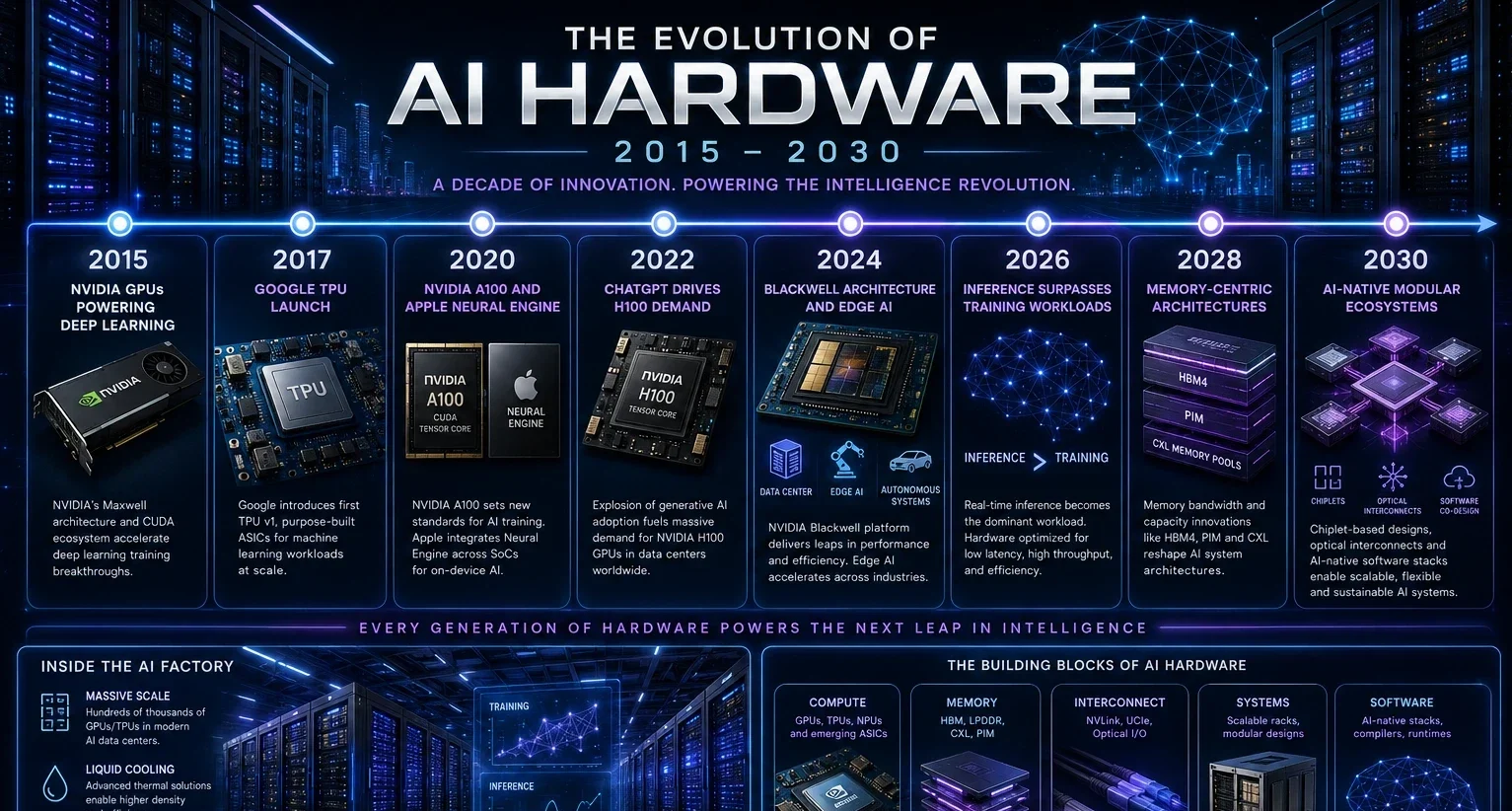
AI Hardware Evolution Timeline (2015-2030)
2015-2016: Deep Learning on GPUs Begins
Researchers discover NVIDIA GPUs dramatically accelerate neural network training. AlexNet, VGGNet, and ResNet establish deep learning viability. CUDA becomes the default AI development environment.
2017: Google TPU v1 Announcement
Google reveals it has been running custom AI chips in production for over a year, demonstrating that alternatives to GPUs can deliver superior economics for specific workloads. The announcement validates custom silicon investment.
2020: NVIDIA A100 and Apple M1 Neural Engine
NVIDIA’s A100 establishes new performance benchmarks for datacenter AI with 312 teraflops and multi-instance GPU capabilities. Apple’s M1 brings 11 TOPS Neural Engine to consumer devices, foreshadowing edge AI proliferation.
2022: ChatGPT Drives H100 Demand Surge
The release of ChatGPT creates unprecedented consumer awareness of AI capabilities and triggers exponential growth in inference workload demand. NVIDIA H100 allocations extend months into the future as latest trends in AI hardware shift toward inference optimization.
2024: Blackwell Architecture and Edge AI Mainstream
NVIDIA’s Blackwell architecture delivers 20 petaflops through multi-die chiplet design. Smartphone manufacturers ship devices with NPUs exceeding 30 TOPS. Edge AI transitions from specialty applications to mainstream features.
2026: Inference Exceeds Training Workload Volume (Projected)
Industry analysts project the crossover point where aggregate inference computing exceeds training workloads, fundamentally shifting hardware optimization priorities and investment. Custom inference accelerators capture significant market share from GPUs.
2028: Memory-Centric Architectures Dominate (Projected)
Processing-in-memory and near-memory computing solutions become standard in AI accelerators as memory bandwidth bottlenecks prove more constraining than compute limitations. Traditional compute-centric metrics become secondary to memory performance specifications.
2030: AI-Native Hardware Ecosystems (Projected)
Complete ecosystems of modular chiplets, optical interconnects, and specialized accelerators for different AI operations replace general-purpose architectures. The distinction between “AI chip” and “processor” becomes meaningless as all computing infrastructure optimizes for machine learning workloads.
What the Timeline Shows
This timeline shows the latest trends in AI hardware as evolutionary rather than revolutionary, each generation builds on discoveries and limitations of the previous wave while introducing innovations that enable the next architectural leap.
Conclusion
The five waves of AI hardware evolution reveal an industry transitioning from accidental GPU dominance toward purpose-built, memory-centric, modular architectures optimized for the specific mathematics of neural networks. Understanding these latest trends in AI hardware matters because the decisions companies make today about infrastructure investment will determine their competitive position for the next decade.
For Developers and Engineers
The practical implication is diversification away from single-vendor dependence. While NVIDIA GPUs remain the pragmatic choice for flexibility and ecosystem maturity, evaluating custom silicon for production inference workloads could deliver significant cost savings and performance improvements. The maturing software abstractions like OpenXLA reduce switching costs between hardware platforms, making architectural choices less permanent than during the CUDA lock-in era.
For Investors and Business Strategists
The most significant opportunity lies not in chips themselves but in the infrastructure required to support them: advanced packaging, memory manufacturing, cooling solutions, and software tooling. The companies that solve memory bandwidth limitations through processing-in-memory or eliminate chiplet interconnect bottlenecks through superior packaging will capture disproportionate value as the latest trends in AI hardware increasingly emphasize integration over raw performance.
The Strategic Inflection Point
The strategic inflection point happening now is the recognition that AI computing isn’t a specialized niche but the future foundation of all computing. The latest trends in AI hardware aren’t side developments that leave traditional computing unchanged; they represent the transformation of computing itself toward AI-native architectures where neural network operations become as fundamental as arithmetic operations were to previous processor generations. The question isn’t whether this transformation happens, but which architectures, companies, and ecosystems emerge as the standards around which the industry consolidates.





